'little brother' integrations via Java12/19/2017 “little brother” runs in two language VM’s on the Raspberry PI. The first, Pharo, I’ve discussed at some length. The second I haven’t, partly because it’s better known, but partly because the use case has become clearer during development. It is the Java VM, specifically used with OSGi in the form of Eclipse Kura.
While Pharo Smalltalk is very good for analytic programs, Java is the best language for integration, since there is more code to integrate written in it, and a vast number of available integration tools and technologies. The addition of Apache Synapse provides both a communications facility for interoperability and a means of throttling distributed queries in the event the Raspberry is too busy to handle the query request immediately. It also provides a means by which the other language VM, Pharo, can send data via StOMP and have the data cleaned and stored separately from the private data in Pharo. The included complex event processor in Synapse aids analysis by breaking down complex events via a rules-based engine. Kura provides an environment where the distributed query module can run locally, lowering the requirements on the cloud based microcontainer by performing preliminary result filtering in the device. Pharo and Kura support about the same number of Raspberry sensors and other devices, but the supported sets are not the same, hence more sensors and devices can be supported by the two containers than by either alone, without the need to write a lot of low-level drivers. The number of analytic tools written in Java, and specifically in Eclipse based OSGi (such as DEVS, Carrot2, GAMA, Capella etc.), provides remote civil engineers with specific competencies in specialized problem areas who may use those tools, or may have written their own tools in Java, with the ability to assist the local engineer to analyze cleaned data on the device. The combination of CM events and Eclipse Aether allows the Kura container to pull such code from public or private Nexus repositories By combining Vert.x with Apache River 3.0 and integrating them with the Synapse micro-ESB, analytic code written in any language supported by Vert.x (JavaScript, Scala, Clojure, etc.) can pull cleaned data to the remote engineer’s own system, then analyze it using any analysis tooling available in nearly any current language. Vert.x also provides a means for writing additional services for the platform in whatever language the developer or engineer prefers, and making those services discoverable. Apache River extends registration and discoverability over the full network and incorporates security to provide access without the need to make every service public. A loosely coupled network of Synapse-based identity servers allows SSO style interoperability between public and private identity servers. A secure chat service, accessible from either Smalltalk or Java, including standalone clients and SWT plugins that can run in Eclipse or IdeaJ, allows a local engineer to chat with remote civil or software engineers to figure out how to analyze a specific event pattern or what code needs to be written to do so. The service uses 4-way handshaking that allows near-equivalent security to a pre-shared key system, without the need to pre-share a key with the resulting difficulties in distributing keys. The protocol used by the service will also be available within Synapse, providing an additional secure data transmission method. Other Java/Eclipse based technologies used include: · Net4j to efficiently synchronize individual device CDO repositories with a device aggregator repository in the situation where multiple devices monitor a single entity (for instance a bridge or apartment building) · UMMISCO GAMA, an Eclipse based infrastructure modeling tool · Capella, an Eclipse based device modeling tool to reconfigure the Raspberry PI and/or add new features to the device · DEVS 3.0, an Eclipse-based toolkit for modeling problem patterns; Carrot2, an Eclipse-based topic clustering facility to cluster relevant online documentation · Concierge, a small-footprint OSGi container suitable for the distributed query engine in the cloud microcontainers · IBM Data Studio, an Eclipse-based data modeling tool that works with the virtual table construction utilized by the distributed query engine to filter and return only relevant results · MSF4J, an OSGi based microservices framework for short lived services, providing an average startup time 1/10th of the equivalent SpringBoot service · WSO2 IS, a Synapse-based identity server providing credentials via Apache River, allowing the creation of an unlimited number of loosely coupled, distributed or federated identity servers rather than a single identity server, providing both low resource requirements for individual identity server services and the option of federating private and public identity services
0 Comments
“little brother” runs in two language VM’s on the Raspberry PI. The first, Pharo, I’ve discussed at some length. The second I haven’t, partly because it’s better known, but partly because the use case has become clearer during development. It is the Java VM, specifically used with OSGi in the form of Eclipse Kura. While Pharo Smalltalk is very good for analytic programs, Java is the best language for integration, since there is more code to integrate written in it, and a vast number of available integration tools and technologies. The addition of Apache Synapse provides both a communications facility for interoperability and a means of throttling distributed queries in the event the Raspberry is too busy to handle the query request immediately. It also provides a means by which the other language VM, Pharo, can send data via StOMP and have the data cleaned and stored separately from the private data in Pharo. The included complex event processor in Synapse aids analysis by breaking down complex events via a rules-based engine. Kura provides an environment where the distributed query module can run locally, lowering the requirements on the cloud based microcontainer by performing preliminary result filtering in the device. Pharo and Kura support about the same number of Raspberry sensors and other devices, but the supported sets are not the same, hence more sensors and devices can be supported by the two containers than by either alone, without the need to write a lot of low-level drivers. The number of analytic tools written in Java, and specifically in Eclipse based OSGi (such as DEVS, Carrot2, GAMA, Capella etc.), provides remote civil engineers with specific competencies in specialized problem areas who may use those tools, or may have written their own tools in Java, with the ability to assist the local engineer to analyze cleaned data on the device. The combination of CM events and Eclipse Aether allows the Kura container to pull such code from public or private Nexus repositories By combining Vert.x with Apache River 3.0 and integrating them with the Synapse micro-ESB, analytic code written in any language supported by Vert.x (JavaScript, Scala, Clojure, etc.) can pull cleaned data to the remote engineer’s own system, then analyze it using any analysis tooling available in nearly any current language. Vert.x also provides a means for writing additional services for the platform in whatever language the developer or engineer prefers, and making those services discoverable. Apache River extends registration and discoverability over the full network and incorporates security to provide access without the need to make every service public. A loosely coupled network of Synapse-based identity servers allows SSO style interoperability between public and private identity servers. A secure chat service, accessible from either Smalltalk or Java, including standalone clients and SWT plugins that can run in Eclipse or IdeaJ, allows a local engineer to chat with remote civil or software engineers to figure out how to analyze a specific event pattern or what code needs to be written to do so. The service uses 4-way handshaking that allows near-equivalent security to a pre-shared key system, without the need to pre-share a key with the resulting difficulties in distributing keys. The protocol used by the service will also be available within Synapse, providing an additional secure data transmission method. Other Java/Eclipse based technologies used include: · Net4j to efficiently synchronize individual device CDO repositories with a device aggregator repository in the situation where multiple devices monitor a single entity (for instance a bridge or apartment building) · UMMISCO GAMA, an Eclipse based infrastructure modeling tool · Capella, an Eclipse based device modeling tool to reconfigure the Raspberry PI and/or add new features to the device · DEVS 3.0, an Eclipse-based toolkit for modeling problem patterns; Carrot2, an Eclipse-based topic clustering facility to cluster relevant online documentation · Concierge, a small-footprint OSGi container suitable for the distributed query engine in the cloud microcontainers · IBM Data Studio, an Eclipse-based data modeling tool that works with the virtual table construction utilized by the distributed query engine to filter and return only relevant results · MSF4J, an OSGi based microservices framework for short lived services, providing an average startup time 1/10th of the equivalent SpringBoot service · WSO2 IS, a Synapse-based identity server providing credentials via Apache River, allowing the creation of an unlimited number of loosely coupled, distributed or federated identity servers rather than a single identity server, providing both low resource requirements for individual identity server services and the option of federating private and public identity services · OpenHAB, an Eclipse-based server system to incorporate sitemaps and other relevant information, and eventing, used in conjunction with a device aggregator for monitoring complex structures Pharo Smalltalk Resource Usage11/27/2017 One of the reasons for using Pharo, aside from the ease of controlling the hardware via object representations down to the pin level, is the relatively low resource usage compared with other IoT environments. The task manager screenshot below is of a Pharo instance which includes:
A deployment image containing the base development tools for remote debugging and code changes, little brother, and closure common lisp integrated, will use ~65 MB RAM. On an 8 thread I7 the maximum CPU usage I’ve seen in development (while test compiling a large project) was just over 29%. Running “little brother” under normal collection / pattern matching usage on the Raspberry PI 2 the maximum recorded in test was 22% of the ARM processor. While remoting the full IDE it peaked at 72% while loading and test compiling the ORM. The 64-bit VM for Linux and OS X uses about 20% more memory than the 32-bit VM, but since the ARM processor is 32-bit, I’m doing development now on a decent spec laptop with Windows 10 and Linux Mint 18 in a dual boot configuration, and a MacBook Pro for the OS X and iOS analysis interfaces. There is an alternate open source VM written by IBM to test the scalability of VM based languages which scaled to 1024 processors with 8 threads each nearly linearly. IBM didn’t have a bigger machine to test on. The Windows task manager screenshot, profiler output and a sample debug log are below, showing the memory usage, performance of individual collection classes and the garbage collector, and the ease of reading debug logs compared with other object languages. Windows Task Manager Output: 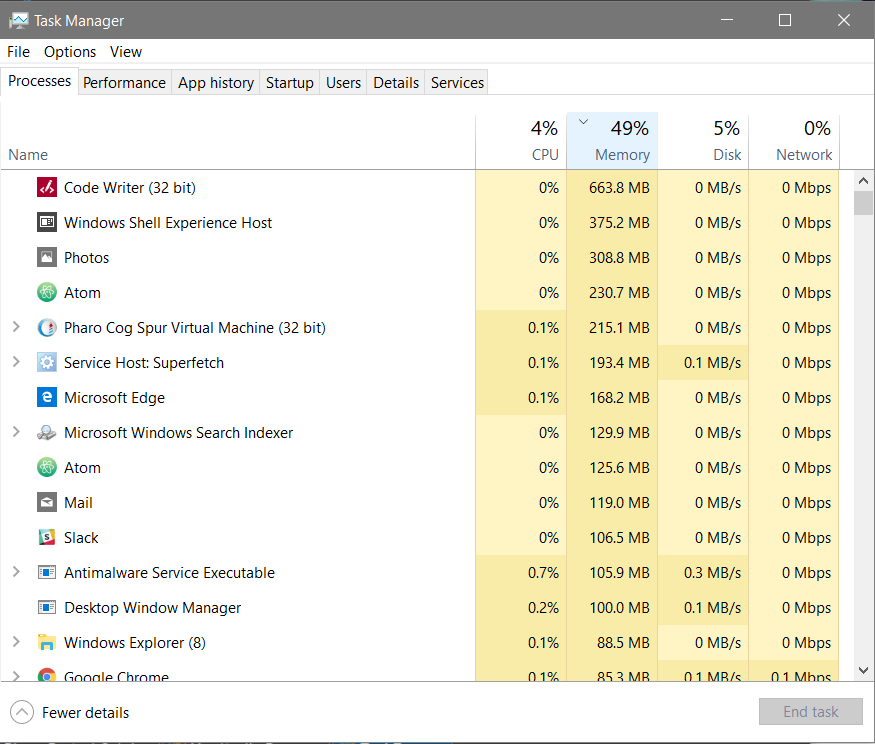 Profiler output:
Tests: 4843 runs, 4843 passes, 0 skipped, 0 expected failures, 0 failures, 0 errors, 0 unexpected passes - 19727 tallies, 19789 msec. **Tree** -------------------------------- Process: (40s) Morphic UI Process: nil -------------------------------- 32.5% {6438ms} TestRunner>>runTestSuites: 32.5% {6438ms} CurrentExecutionEnvironment class>>runTestsBy: 32.5% {6438ms} DefaultExecutionEnvironment>>runTestsBy: 32.5% {6438ms} TestExecutionEnvironment(ExecutionEnvironment)>>beActiveDuring: 32.5% {6438ms} CurrentExecutionEnvironment class>>activate:for: 32.5% {6438ms} BlockClosure>>ensure: 32.5% {6438ms} CurrentExecutionEnvironment class>>activate:for: 32.5% {6438ms} TestRunner>>runTestSuites: 32.5% {6438ms} Set(Collection)>>do:displayingProgress: 32.5% {6438ms} Set(Collection)>>do:displayingProgress:every: 32.5% {6438ms} ByteString(String)>>displayProgressFrom:to:during: 32.5% {6438ms} MorphicUIManager(UIManager)>>displayProgress:from:to:during: 32.5% {6438ms} Job>>run 32.5% {6438ms} BlockClosure>>ensure: 32.5% {6436ms} Job>>run 32.5% {6432ms} CurrentJob class(DynamicVariable class)>>value:during: 32.5% {6432ms} CurrentJob(DynamicVariable)>>value:during: 32.5% {6432ms} BlockClosure>>ensure: 32.5% {6432ms} CurrentJob(DynamicVariable)>>value:during: 32.5% {6432ms} Job>>run 32.5% {6432ms} BlockClosure>>cull: 32.5% {6432ms} Set(Collection)>>do:displayingProgress:every: 32.5% {6422ms} Set>>do: 32.5% {6422ms} Set(Collection)>>do:displayingProgress:every: 32.4% {6404ms} TestRunner>>runTestSuites: 32.4% {6402ms} TestRunner>>runSuite: 30.6% {6046ms} TestRunner>>executeSuite:as: |30.6% {6046ms} BlockClosure>>ensure: | 30.6% {6046ms} TestRunner>>executeSuite:as: | 30.6% {6046ms} BlockClosure>>cull:cull: | 30.6% {6046ms} TestRunner>>runSuite: | 30.6% {6046ms} TestSuite>>run: | 30.6% {6046ms} CurrentExecutionEnvironment class>>runTestsBy: | 30.6% {6046ms} TestExecutionEnvironment>>runTestsBy: | 30.6% {6046ms} TestSuite>>run: | 30.6% {6046ms} TestSuite>>runUnmanaged: | 30.6% {6046ms} BlockClosure>>ensure: | 30.6% {6046ms} TestSuite>>runUnmanaged: | 30.6% {6046ms} OrderedCollection>>do: | 30.6% {6046ms} TestSuite>>runUnmanaged: | 30.1% {5955ms} ReadStreamTest(TestCase)>>run: | 30.1% {5955ms} TestResult>>runCase: | 30.1% {5955ms} BlockClosure>>on:do: | 30.1% {5955ms} TestResult>>runCase: | 30.1% {5955ms} ReadStreamTest(TestCase)>>runCaseManaged | 30.1% {5955ms} CurrentExecutionEnvironment class>>runTestCase: | 30.1% {5955ms} TestExecutionEnvironment>>runTestCase: | 29.5% {5829ms} BlockClosure>>ifCurtailed: | 29.5% {5829ms} TestExecutionEnvironment>>runTestCase: | 29.5% {5829ms} BlockClosure>>ensure: | 29.5% {5829ms} TestExecutionEnvironment>>runTestCase: | 25.1% {4977ms} TestExecutionEnvironment>>runTestCaseSafelly: | |25.1% {4977ms} BlockClosure>>on:do: | | 25.1% {4977ms} TestExecutionEnvironment>>runTestCaseSafelly: | | 25.1% {4977ms} BlockClosure>>on:do: | | 25.1% {4977ms} TestExecutionEnvironment>>runTestCaseSafelly: | | 25.1% {4977ms} BagTest(TestCase)>>runCase | | 25.1% {4977ms} FullBlockClosure(BlockClosure)>>ensure: | | 24.9% {4921ms} BagTest(TestCase)>>runCase | | 23.6% {4668ms} BagTest(TestCase)>>performTest | | |4.9% {967ms} BagTest(ClassTestCase)>>testMethodsOfTheClassShouldNotBeRepeatedInItsSuperclasses | | | |4.9% {967ms} BagTest(ClassTestCase)>>assertValidLintRule: | | | | 4.9% {965ms} SmalllintManifestChecker(RBSmalllintChecker)>>run | | | | 3.3% {658ms} RBClassEnvironment(RBBrowserEnvironment)>>classesAndTraits | | | | |3.3% {658ms} RBClassEnvironment(RBBrowserEnvironment)>>classesAndTraitsDo: | | | | | 3.3% {658ms} RBClassEnvironment(RBBrowserEnvironment)>>allClassesAndTraitsDo: | | | | | 3.3% {658ms} SystemDictionary>>allClassesAndTraitsDo: | | | | | 3.3% {654ms} OrderedCollection>>do: | | | | | 3.1% {614ms} SystemDictionary>>allClassesAndTraitsDo: | | | | | 2.7% {539ms} RBClassEnvironment(RBBrowserEnvironment)>>classesAndTraitsDo: | | | | | 2.6% {523ms} RBClassEnvironment>>includesClass: | | | | | 1.7% {327ms} ByteSymbol class(ClassDescription)>>isMeta | | | | 1.6% {307ms} Array(Collection)>>do:displayingProgress: | | | | 1.6% {307ms} Array(Collection)>>do:displayingProgress:every: | | | | 1.6% {307ms} ByteString(String)>>displayProgressFrom:to:during: | | | | 1.6% {307ms} MorphicUIManager(UIManager)>>displayProgress:from:to:during: | | | | 1.5% {303ms} Job>>run | | | | 1.5% {303ms} BlockClosure>>ensure: | | |4.4% {871ms} WeakOrderedCollectionTest>>testWeakOrderedCollectionSomeGarbageCollected | | | |4.4% {869ms} SmallInteger(Integer)>>timesRepeat: | | |4.4% {867ms} WeakOrderedCollectionTest>>testWeakOrderedCollectionAllGarbageCollected | | | |4.4% {864ms} SmallInteger(Integer)>>timesRepeat: | | |4.3% {847ms} BagTest(ClassTestCase)>>testTraitExplicitRequirementMethodsMustBeImplementedInTheClassOrInASuperclass | | | |4.3% {847ms} BagTest(ClassTestCase)>>assertValidLintRule: | | | | 4.3% {847ms} SmalllintManifestChecker(RBSmalllintChecker)>>run | | | | 3.3% {649ms} RBClassEnvironment(RBBrowserEnvironment)>>classesAndTraits | | | | 3.3% {647ms} RBClassEnvironment(RBBrowserEnvironment)>>classesAndTraitsDo: | | | | 3.3% {647ms} RBClassEnvironment(RBBrowserEnvironment)>>allClassesAndTraitsDo: | | | | 3.3% {647ms} SystemDictionary>>allClassesAndTraitsDo: | | | | 3.2% {642ms} OrderedCollection>>do: | | | | 3.2% {628ms} SystemDictionary>>allClassesAndTraitsDo: | | | | 2.7% {542ms} RBClassEnvironment(RBBrowserEnvironment)>>classesAndTraitsDo: | | | | 2.6% {521ms} RBClassEnvironment>>includesClass: | | | | 1.7% {332ms} AthensCanvas class(ClassDescription)>>isMeta | | | | 1.2% {231ms} AthensCanvas class(ClassDescription)>>isClassSide | | |1.7% {336ms} ByteSymbolTest>>testReadFromString | | | |1.5% {299ms} Array(SequenceableCollection)>>select: | | |1.6% {319ms} ByteSymbolTest>>testAs | | | |1.4% {287ms} Array(SequenceableCollection)>>select: | | |1.5% {296ms} ByteSymbolTest>>testNewFrom | | | 1.4% {270ms} Array(SequenceableCollection)>>select: | | 1.3% {254ms} WeakIdentityKeyDictionaryTest(WeakKeyDictionaryTest)>>setUp | | 1.2% {228ms} Array(SequenceableCollection)>>do: | | 1.1% {222ms} WeakIdentityKeyDictionaryTest(WeakKeyDictionaryTest)>>setUp | | 1.0% {200ms} WeakKeyDictionary>>at:put: | 4.3% {853ms} primitives 1.8% {356ms} TestRunner>>updateResults 1.8% {348ms} TestRunner>>updateStatus: 1.8% {348ms} TestRunner(Model)>>changed: 1.8% {348ms} DependentsArray>>do: 1.8% {348ms} TestRunner(Model)>>changed: 1.8% {348ms} PluggableTextFieldMorph>>update: 1.8% {348ms} PluggableTextFieldMorph(PluggableTextMorph)>>update: 1.4% {278ms} PluggableTextFieldMorph>>getText 1.4% {278ms} TestRunner>>statusText 1.4% {278ms} TestResult(Object)>>printString 1.4% {278ms} TestResult(Object)>>printStringLimitedTo: 1.4% {278ms} String class(SequenceableCollection class)>>streamContents:limitedTo: 1.4% {278ms} TestResult(Object)>>printStringLimitedTo: 1.4% {278ms} TestResult>>printOn: 1.4% {270ms} TestResult>>runCount 1.3% {262ms} TestResult>>passedCount 1.3% {259ms} TestResult>>passed 1.3% {257ms} TestResult>>expectedPasses 1.3% {257ms} OrderedCollection>>select: 1.3% {257ms} TestResult>>expectedPasses 1.3% {257ms} BagTest(TestCase)>>shouldPass 1.3% {257ms} BagTest(TestCase)>>isExpectedFailure 1.3% {255ms} BagTest(TestCase)>>expectedFailures 1.3% {253ms} Pragma class>>allNamed:from:to: 1.3% {253ms} Array class(SequenceableCollection class)>>streamContents: 1.3% {253ms} Array class(SequenceableCollection class)>>new:streamContents: 1.3% {253ms} Pragma class>>allNamed:from:to: 1.3% {253ms} BagTest class(Behavior)>>withAllSuperclassesDo: **Leaves** 8.8% {1732ms} SmallInteger(Integer)>>timesRepeat: 4.9% {978ms} TestExecutionEnvironment>>runTestCase: 2.6% {520ms} Array(SequenceableCollection)>>select: 1.6% {311ms} GLMTreeMorphModel class(Class)>>name 1.4% {276ms} ByteString(String)>>= 1.2% {240ms} ByteSymbol class(ClassDescription)>>isMeta **Memory** old +0 bytes young +1,524,464 bytes used +1,524,464 bytes free -1,524,464 bytes **GCs** full 34 totalling 14,731ms (74.0% uptime), avg 433.0ms incr 168 totalling 301ms (2.0% uptime), avg 2.0ms tenures 29,787 (avg 0 GCs/tenure) root table 0 overflows Sample Debug Log: THERE_BE_DRAGONS_HERE Debug 26 November 2017 2:32:15.457907 pm VM: Win32 - IX86 - 10.0 - CoInterpreter VMMaker.oscog-eem.2254 uuid: 4f2c2cce-f4a2-469a-93f1-97ed941df0ad Jul 20 2017 StackToRegisterMappingCogit VMMaker.oscog-eem.2252 uuid: 2f3e9b0e-ecd3-4adf-b092-cce2e2587a5c Jul 20 2017 VM: 201707201942 https://github.com/OpenSmalltalk/opensmalltalk-vm.git $ Date: Thu Jul 20 12:42:21 2017 -0700 $ Plugins: 201707201942 https://github.com/OpenSmalltalk/opensmalltalk-vm.git $ Image: Pharo6.0 [Latest update: #60520] Process>>debugWithTitle: Receiver: a Process in nil Arguments and temporary variables: title: 'Debug' context: Process>>debugWithTitle: Receiver's instance variables: nextLink: nil suspendedContext: nil priority: 40 myList: nil name: 'Morphic UI Process' env: a WeakArray(nil nil nil nil nil nil nil a Job nil nil) effectiveProcess: nil terminating: false Process>>debug Receiver: a Process in nil Arguments and temporary variables: Receiver's instance variables: nextLink: nil suspendedContext: nil priority: 40 myList: nil name: 'Morphic UI Process' env: a WeakArray(nil nil nil nil nil nil nil a Job nil nil) effectiveProcess: nil terminating: false Job>>debug Receiver: a Job Arguments and temporary variables: Receiver's instance variables: block: load RPackageSet withCacheDo: [ | version | version := versions fi...etc... currentValue: 0 min: 0 max: 100 title: 'Loading ConfigurationOfTestsUsageAnalyser-BenoitVerhaeghe.1503412210' children: an OrderedCollection(a Job) isRunning: true parent: a Job process: a Process in nil JobProgressMorph>>debug Receiver: a JobProgressMorph(555060992) Arguments and temporary variables: Receiver's instance variables: bounds: ([email protected]) corner: ([email protected]) owner: a SystemProgressMorph(135007232) submorphs: an Array(a StringMorph(252225280)'Loading ConfigurationOfTestsUsageA...etc... fullBounds: (31@65) corner: (469@98) color: Color transparent extension: a MorphExtension (19710976) [other: (announcer -> an Announcer)] bar: a JobProgressBarMorph(867591168) endValue: nil hasResult: false job: a Job labelMorph: a StringMorph(252225280)'Loading ConfigurationOfTestsUsageAnalyser-...etc... lastRefresh: 0 lock: a Semaphore() result: nil startValue: nil MorphEventSubscription>>notify:from: Receiver: a MorphEventSubscription Arguments and temporary variables: anEvent: [(282@92) mouseUp 69360937 nil] sourceMorph: a JobProgressBarMorph(867591168) arity: 0 Receiver's instance variables: event: #mouseUp selector: #debug recipient: a JobProgressMorph(555060992) valueParameter: nil result in MorphicEventHandler>>notifyMorphsOfEvent:ofType:from: Receiver: a MorphicEventHandler Arguments and temporary variables: result: false anEvent: a MorphEventSubscription eventType: a JobProgressBarMorph(867591168) sourceMorph: [(282@92) mouseUp 69360937 nil] Receiver's instance variables: subscriptions: a Dictionary(#mouseUp->a Set(a MorphEventSubscription) ) Set>>do: Receiver: a Set(a MorphEventSubscription) Arguments and temporary variables: aBlock: result index: 4 each: a MorphEventSubscription Receiver's instance variables: tally: 1 array: an Array(nil nil nil a MorphEventSubscription nil) Difficulties to be Solved11/26/2017 Some of the main difficulties in completing the “little brother” infrastructure analysis IoT Initiative include:
· Lack of available studies on critical physical infrastructure. Largely only bridges have undergone any analysis, and that analysis was limited to the state of Indiana. · Lack of infrastructure deterioration models. The Markov models are a bit simplistic and primarily geared to visual inspections. The more consistent pattern matching and correlations with available public information (weather, etc.) should improve the models, but as with other aspects it will depend on the usage and will only improve over time. · Lack of good modeling tools for the models needed for contextual analysis. The combination of IDENGINE and the Infrastructure Workbench will need to be integrated with the Pharo data collection and analysis tools. · The models themselves will need to be constantly regenerated from the changing data. ACT-R is a good framework for dynamic regeneration of pattern matching and poisson based models, and to determine the quality of the heuristics used by the engineer themselves on specific problem types. The current pattern matching / deviation code is built in ACT-R for that reason. The ease of writing custom scripts and modifying the initial source manually will also help in improving the tooling. · Average costs for repairing / replacing infrastructure are unavailable. By having infrastructure engineers enter the final cost a relatively accurate average can be determined over time. The larger and more geographically diverse the user base, the more accurate the estimates will become. · The success of the initiative is highly dependent on the size and diversity of the system’s usage. The lack of tools currently available makes that usage far more likely, but assistance in making the hardware affordable will also increase usage, particularly in the targeted poorer areas of the world and of different areas of individual cities. “little brother” Analysis Tools11/26/2017 The Pharo Smalltalk Environment To understand how the query, analysis and visualization tools work, a short overview of the Pharo Smalltalk environment in which they run is necessary. The following refers to the code analysis tools written earlier, and on which the infrastructure analysis will be based, but with different models based on infrastructure engineering standards. Smalltalk is a live object environment. If you’re familiar with other live environments, such as the Emacs LISP console or the Python console, the Smalltalk environment is similar in that arbitrary code can be typed in (in Smalltalk, the area in which you type arbitrary code is not a console, but a text area known as a ‘playground’) and executed immediately without a compile/build cycle. For example, typing ‘MessageFlowBrowser new open’ in the playground and executing it instantiates a MessageFlowBrowser object, which then appears in the workspace and can be used. Unlike a Python console, where the text is interpreted as a keyword command, Smalltalk has no keywords. ‘MessageFlowBrowser’ is a reference to the class object for the MessageFlowBrowser class, and all class objects are loaded at startup. The new ‘command’ is a message, which in Smalltalk is an arbitrary dynamic object with no fields or methods. The actual method called is ‘initialize’. This indirection, where the class being called determines how to respond to a message, or a binary message with an object, provides a simpler call for the class’ clients. It also ensures the author of the class determines how the class can be called, rather than the author of the calling class having to figure out from parameter names what specific variables to pass in, which is often difficult to determine without access to the source. Class and instance objects understand various messages by convention, design or via inheritance. By comparison with other object languages, the base Smalltalk Object and Proto-Object understand a rich set of messages that all Smalltalk objects inherit, including the full set of reflection messages. Classes can have both class variables and methods, and instance variables and methods. All instances of a class have the same value for a variable Since ‘MessageFlowBrowser’ is a reference to an actual object, it can be highlighted, and its state inspected, its code can be browsed and edited, or refactoring tools can be applied to it with the effect occurring as soon as the change is saved. This is the case not just with declared classes and messages, but also with literals and operators. ‘42’, if inspected, is an integer object with the value 42, and will respond to any message that integer objects understand, which include the standard mathematical operators such as +, -, *, /, etc., as well as more complex messages such as factorial. Variables in Smalltalk are dynamic, not in the sense of untyped as with JavaScript, in fact they are strongly typed, but in the sense that they are typed when a value is assigned, and allowable casts are performed implicitly. Thus typing ’42 factorial’ in a playground and executing it gives you a (very large) numerical result, whereas the equivalent in Java will cause an error, since Java will not implicitly cast an integer to a number class large enough to compute the result. If the result is inspected, it is a BigInteger object. Polymorphism in Smalltalk is not like the method based polymorphism in Java, but refers to polymorphic classes. The ‘become’ message allows safe casts between related types. If the cast is unsafe, the environment throws an exception the moment the new code is saved. It needs to be kept in mind is that the entire environment is written in Smalltalk. There is no difference between VM code, interpreter code, JIT compiler code, or user code. Apart from code that calls out to external libraries such as OS libraries, the interpreter or JIT compiler converts the Smalltalk code directly to assembler, and since it is written in Smalltalk, the resulting assembler implicitly follows the rules and restrictions of the language. The usual demarcation of languages into first generation (assembler), second generation (C, Pascal etc., written in assembler), and third or fourth generation (such as Java, written in C and interpreted/compiled by C code, or Groovy, written in Java and precompiled in Java, then interpreted/compiled by C code) is not relevant to Smalltalk. The language, tools, VM, interpreter and JIT compiler are all themselves written in Smalltalk. Since the bootstrapper is no longer operative in Pharo once the base VM and interpreter classes are loaded, the environment contains all the code necessary and contains it all in the same manner. Thus, new code imported from a repository or written by the developer is as much part of the VM as the VM kernel or interpreter, and any of it can be changed dynamically at runtime. The Model Environment Within the tools, a model is a representation of the target code base in FAMIX format. FAMIX models can be generated from various code bases, currently the tools support Smalltalk (unsurprisingly), Java, JavaScript, LISP, Python, SQL and ABAP. Prior to release I plan to support a few other JVM based languages (since converting the respective Eclipse IDE model to FAMIX is relatively trivial), including Scala, Clojure and Ceylon. The FAMIX model, which is stored as a text file with the extension ‘mse’, is imported into the Smalltalk environment, creating model objects based on the FAMIX meta-model. The resulting model is displayed via a UI toolkit designed for developer tools, which provides a ‘sliding pane’ interface with contextual tabs determined by the pane’s content. Thus, a pane containing a Class Group will have different tab options than one containing a Class or a visualization. All the panes contain a query tab; code entered in that tab and executed produces a result that is displayed in the next pane to the right (which is created if it doesn’t yet exist). As an example, in a class group that consists of all the classes in a project, entering the following query will open a new pane and slide the current pane to the left. The new pane will contain all the classes that satisfy the query: Self select: [ :each | each isAnnotatedWith: ‘Deprecated’ ] All Smalltalk objects, including FAMIX model objects, understand the message ‘self’, since it’s implemented in the base Smalltalk Object class. Since the class group is a Smalltalk collection class, it understands the binary message select: with the block object as the second term. Each member of the Class Group is a FamixClass object, and FamixClass objects understand the binary message isAnnotatedWith: aString. In each pane, the last tab shows the meta-model attributes that that model object understands, so the available operations are handy to the query pane. In the situation where we wanted to know what deprecated classes could be simply removed from a code base without causing a problem, we could write a query in the result pane such as this: Self select: [ :each | each clientTypes isEmpty ] This will create another pane with the deprecated classes that are not called by any other classes in the codebase, and can therefore be removed. For the sake of argument, let’s say there were 25 deprecated classes, 14 of which aren’t called by any other class, that leaves 11 deprecated classes that are still referenced. However, it would be nice to know in what way they are referenced: i.e. are the calling classes themselves deprecated? Is a deprecated class called by more than one client class? etc. Code queries aren’t ideal for this kind of analysis, though, so instead we can write a visualization such as this: | view | view := RTMondrian new. view shape circle if: [ :each | each isAnnotatedWith: 'Deprecated' ] color: Color red. view nodes: (self, (self flatCollect: #clientTypes)) asSet. view edges connectFromAll: #clientTypes. view layout force. view view pushBackEdges. view This script uses the Roassal Toolkit and specifically the RTMondrian class, to produce the visualization, the results of which are below: 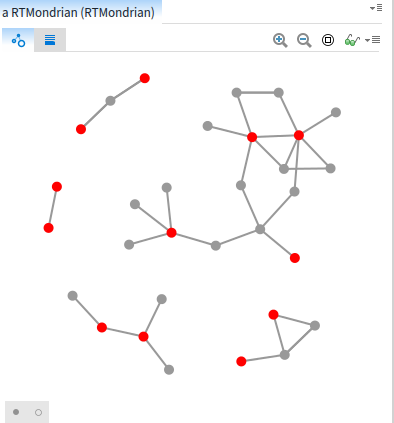 Although the details of how to write a script to produce all the possible visualizations are outside the scope of this overview, there are a couple of things worth noting. The message with the hash, #clientTypes, is known as a symbolic message. Symbolic messages are used by convention to generalize different messages for different object types that have a similar intended meaning. Thus #clientTypes may be interpreted as a different message by a FAMIX class object than by a FAMIX method object, but the use of the symbolic message generalizes the intent such that each responds with the appropriate result.
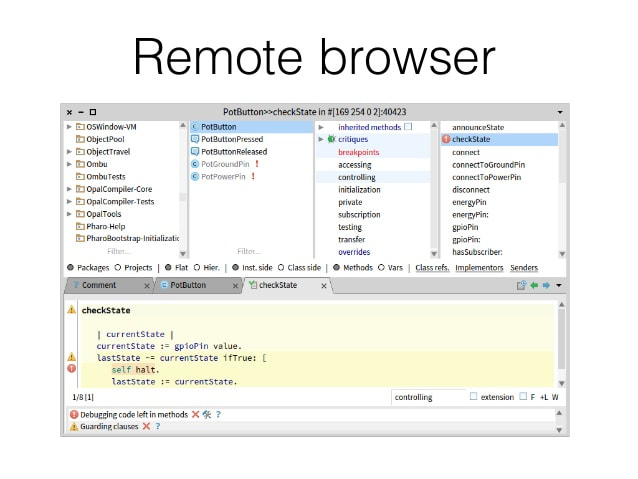
Other tabs that are available, depending on the content of the pane, include a summary (.) on a group of model objects, a UML class diagram in the case of a class or type group, etc. Aside from the pane containing the meta-model information for that pane’s content, there is a separate meta-model browser allowing the engineer to browse the full FAMIX meta-model to find what he or she might be looking for. “little brother” Base Features11/26/2017 1. Raspberry PI / Beaglebone / Arduino pins are modeled as objects. All class objects are live and can be scripted. Model based, scriptable query, analysis and visualization. (leveraging code query tool I wrote earlier this year, shown below) The entire system, VM, language, interpreter and JIT compiler are in the environment as source. The extent of the tooling is beyond most environments. 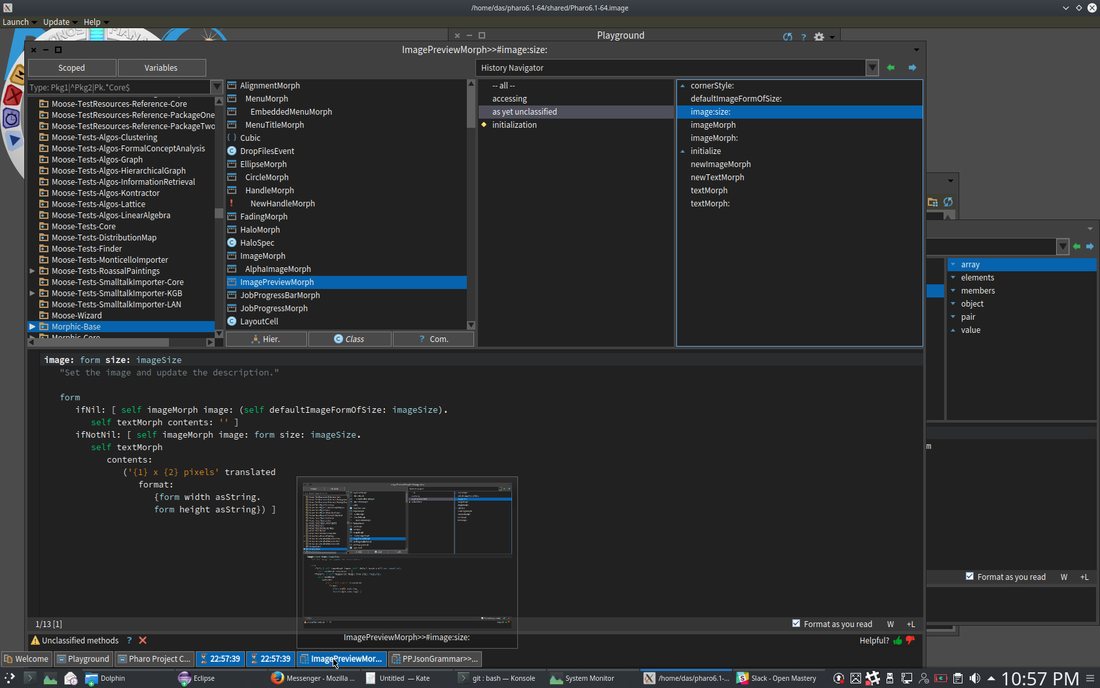 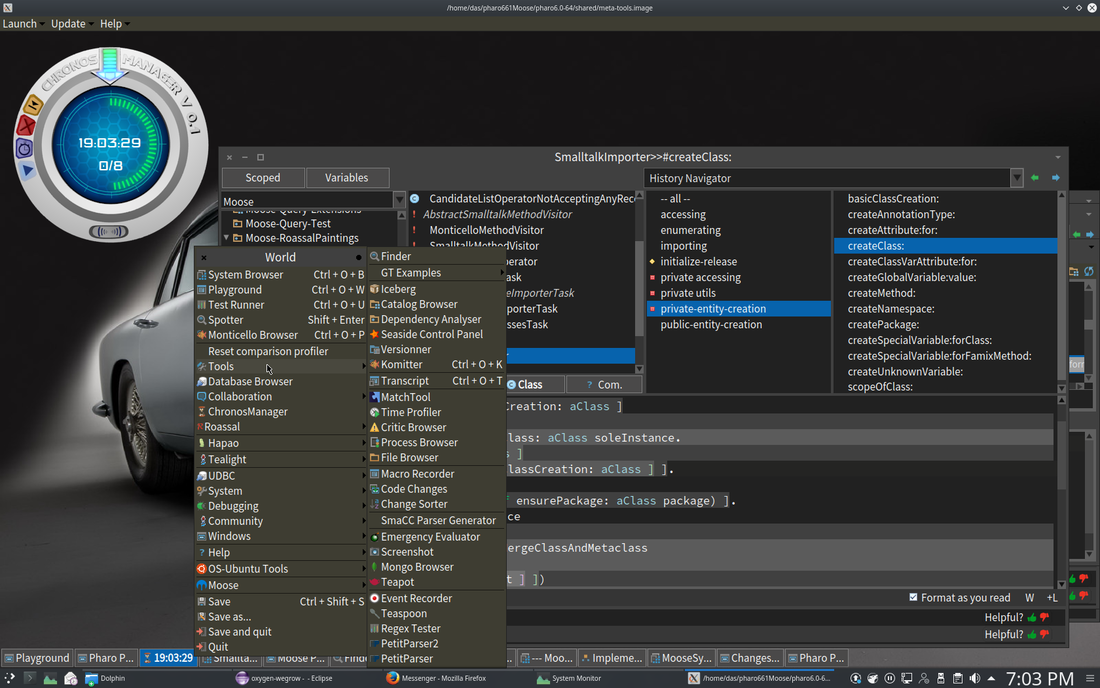 Discord Integration Slideshow - Discord Integration “Data Story” creator, integrating text, data, analyses, multimedia. Exportable to PDF, HTML, LaTEX. HTML can be served by built in web server. 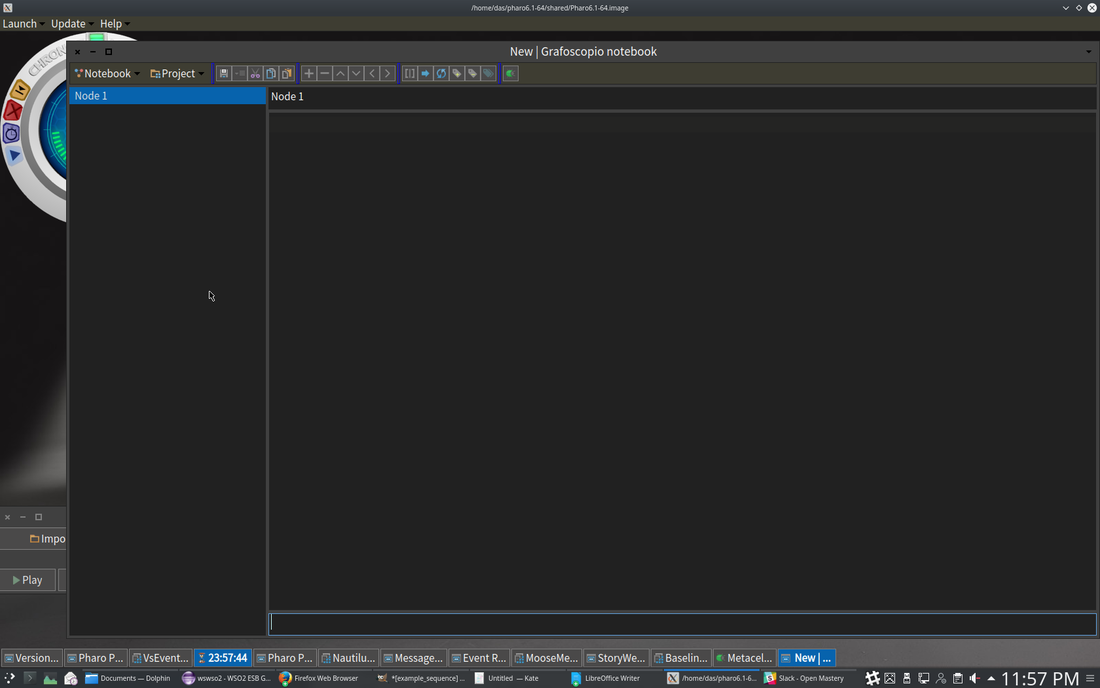 Plenty of Open Source Libraries  'little brother'11/23/2017 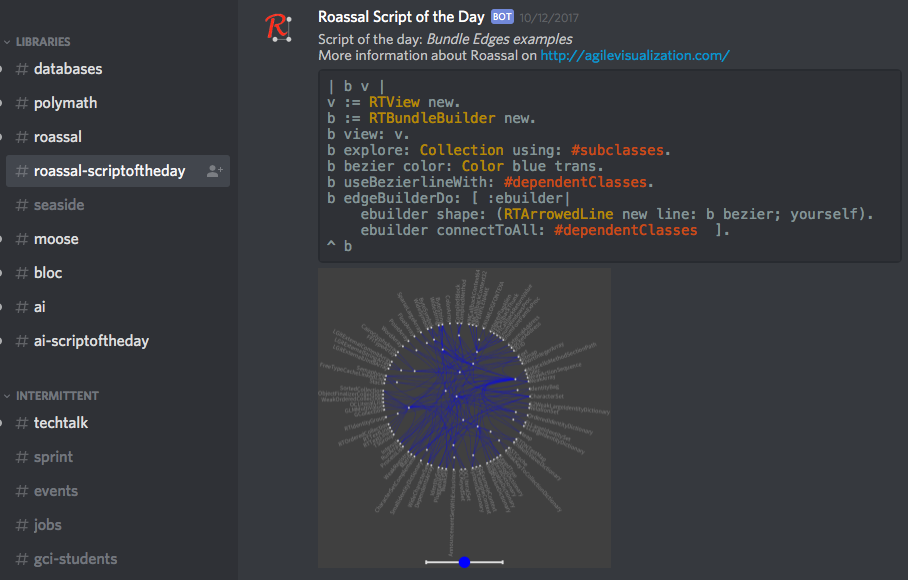 The core notion behind “little brother” is to overcome the inevitable lag between the increase in data volume and increases in available bandwidth and centralized processing power. The insight that drives it is that data is arbitrarily large, grows exponentially, and it is therefore both difficult to move and to analyze, no matter how much initial central computing power you throw at the problem. Moving data and analyzing it centrally also introduces complexity in terms of security of private data both while transferring and while analyzing it. The notion of “Big Brother” from Orwell’s 1984 rests on the assumption that all data could be both centralized and analyzed with sufficient depth that the posited centralized authority would be essentially omniscient. The name of this initiative plays off that, since it doesn’t appear to be inherently possible due to the exponential growth of such data. Maintaining and analyzing data locally is far more efficient, and allows the same overall scope of analysis without the same issues. As a result, “little brother” is a true ‘Internet of Things’ architecture, rather than the ‘CompuServe of Things’ architectures that have been offered by the major vendors. The fastest way to move data of any size is to not move it. Not moving it also eliminates issues around security including public and individual concerns over data ownership, since the data stays with the collector, which can be any individual or group that can afford a Raspberry PI, an inexpensive tablet or netbook, and a cloud microcontainer. It also solves the issue of data growth without corresponding equivalent growth in processing power, since the addition of further data collectors inherently adds further analysis power. The difficulty is having appropriate analysis code where the data already is, capable of performing reasonably fast, complex analyses on that data in the same environment as the collector. “little brother” solves that issue by using a two-container system that together analyze the actual data and store data with all identifying information removed correlated to the analysis code used to analyze it. The code is kept in online repositories, either GIT or Nexus based, and a distributed query that runs across the microcontainers on metadata and into the local container with cleaned data, to find the most appropriate analysis code available and pull it into the running containers where the query originated for use on the new data. The analysis code can be modified via a tablet based UI and immediately tested on the data to view the results. There is no need for any compile / build cycle, since all the code in the environment is live object code. Script snippets etc. can also be shared via Discord chat. The analysis code itself is based on an agile visualization engine, and a UI toolkit developed specifically for crafting custom analyses. It can be used to write a custom analysis in < 15 minutes, once the user becomes familiar with the scripting language. Whether an initial query is scripted, or a perspective simply chosen, the panels slide across horizontally, displaying the data you queried from and the results. The results can then be queried further, at any point a visualization can be created to view the data in a more immediately meaningful way. The data and analysis can be linked with textual information, hyperlinks and other needed artifacts to create reports, journalism and other types of aggregated artifacts in order to be able to communicate a problem with all relevant context, exporting it to common formats such as PDF or LaTEX, or serving it as auto-generated web pages via the built-in web server. It is of course designed with engineers in mind, but not intended only for software engineers, since both the models created from sensor data and the scripting language are easy enough for someone who doesn’t write software for a living to understand and add to their technical arsenal in a short time. Each part of the model can be inspected to get the names of fields and methods needed for the scripts, and any of the source can be viewed to see how it works and modified if necessary, modifications to any of the code take effect the moment the code is saved. The visualization types are available for view in the system in a gallery showing what each type can do, and the code for each example is also there, showing how to use the different visualization capabilities in various situations. The entire system code is in the environment as source, with the exception of the small bootstrapper, including the VM, language, interpreter and JIT compiler, as well as the source to the frameworks being utilized. This also provides the kind of transparency necessary in data journalism / data activism, where the source data and methodologies may need to be validated by a third party. The initial target for the system is in areas with aging infrastructure a lack of significant funding for large scale analysis of the infrastructure. By placing cheap Raspberry PI devices with the appropriate sensors, collecting data which is then built into a model by the system, and finding the best available analysis code as a starting point, infrastructure engineers can look for the beginnings of problems before they become catastrophic. A prime example of such an area is the concentration of ‘high rise slums’ in Hong Kong, many of which are not dissimilar to the now demolished Kowloon Walled City. Lack of maintenance and the sheer size of the infrastructure involved is creating potentially catastrophic situations in Hong Kong and in numerous other cities worldwide, particularly those with significant slum populations and high population densities. An article on the situation, which affects ~3 million people in Hong Kong alone, one of many locales with such areas, is below: https://www.thestar.com/life/2017/05/10/hong-kongs-shoebox-homes-slums-in-the-sky-pose-a-challenge-for-new-leader.html The lack of sufficient funding currently to even understand the scope of the problem implies that the system must run on the cheapest available hardware, with the least necessary bandwidth, and that the cloud microcontainers for distributed queries are truly microcontainers and are therefore either available in free tiers or very close to free. Individual microcontainers with 1 vCPU, 512 RAM and a standard virtual network connection can run a common distribution of Linux (Debian, Ubuntu, Kubuntu, Mint) with sufficient speed to be able to return millions of rows of initial data in response to a query, narrow that down to the best candidate analysis code across nodes, and return that code to the local Raspberry PI in under a minute. Since the distributed query network self-organizes and self-maintains, no additional work is needed beyond simply deploying nodes, a node will be made available with the system as a deployable container to any cloud service, although I personally use Joyent (now owned by Samsung), since Joyent doesn’t reduce network performance on microcontainers as Amazon, Google and others do. The target price point is to be able to distribute the Raspberry PI, sensors, and a tablet or netbook with the requisites to customize the analysis for ~$100-$150, while the microcontainer will run on available cloud services for less than $2/month. The GIT and Nexus repositories needed are publicly available at no cost. It should therefore be possible to make the system available to areas that need the local scope of the problem to be analyzed, have capable people, but little in the way of funding. Once analysis code has been tailored and the analysis completed, the tailored / expanded / changed scripts are correlated to cleaned data and pushed back to one of the available repositories. Data with patterns that are similar to the cleaned data will discover the more appropriate, tailored analysis. Thus, the system’s capabilities grow as analyses are done, just as the total available computing power grows as data collection grows. As a real-world example of the capabilities of the base analysis engine and associated tools, the epidemiology program Kendrick was written with similar base tooling in less than a month by one developer. Kendrick solved the epidemiology of the spread pattern of the Ebola virus, after Google had spent millions on big data analytics and failed to produce relevant results. Big data is good at finding patterns, but hopeless at finding the exceptions to common patterns that most often indicate a problem beginning to manifest. The heading picture displays some of the basic tooling. The notebook facility in the first image allows the user to connect WYSIWYG text with hyperlinks etc. to source data and analyses, and create ‘data stories’ that can be exported to PDF or HTML, or served publicly via the built-in web server with no manual writing of web pages. This allows not only the analysis to be accomplished, but to then be used for data journalism, data activism and other things that might be necessary in such situations, since while the analysis may be accomplished inexpensively, problems discovered may require much more serious funding to fix. While the core Raspberry PI code is currently in test, I’m currently using the analysis and data story toolkit on publicly available data to present a cogent case of the scope of the problem, and the need for a solution that at least begins the process of eventually fixing “technical debt” that could prove far more harmful to far more people than the kind software developers are more accustomed to. AuthorAndrew Glynn, Owner, architect and developer, philosopher, and soccer fan. ArchivesCategories |








 RSS Feed
RSS Feed
